Содержание
TailSlayer — экспериментальный метод, который снижает почти худшие задержки доступа к DRAM до 93,3% за счёт «подстраховки» обращений к памяти. Автор идеи — исследователь безопасности LaurieWired. Трюк работает и на x86, и на Arm, но платой становятся дублирование данных, расход памяти и CPU-ядер.
Проблема старая, ещё со времён появления DRAM в 1960-х. Память нужно постоянно обновлять, потому что ячейки — это крошечные «подтекающие» конденсаторы. Обновление идёт с интервалами в микросекундах, и иногда запрос попадает в окно refresh.
Тогда доступ к памяти просто ждёт конца цикла. Задержка может составлять сотни наносекунд. В абсолютных цифрах это мелочь, но даже 200 нс — это до тысячи тактов простоя для современного ядра CPU.

Как TailSlayer борется с DRAM refresh stalls
Идея TailSlayer в том, чтобы не пытаться предсказать refresh, а обойти его статистикой. LaurieWired дублирует рабочий набор данных так, чтобы копии лежали на разных физических каналах памяти с независимыми таймингами. Затем вычисления запускаются параллельно на двух (или больше) ядрах, каждое обращается к своей копии, а система берёт результат того потока, который закончил первым.
Если один поток упирается в refresh-столл, шанс, что второй попадёт в тот же момент, ниже. Так метод и «срезает хвост» распределения задержек, то есть tail latency.

Цифры: от Ryzen на десктопе до 12 каналов EPYC
На потребительской системе с Ryzen TailSlayer сократил near-worst-case задержки доступа к DRAM более чем вдвое. На серверных платформах эффект оказался сильнее. Там часто ниже частоты CPU, медленнее память и консервативнее тайминги, поэтому refresh-столлы заметнее.
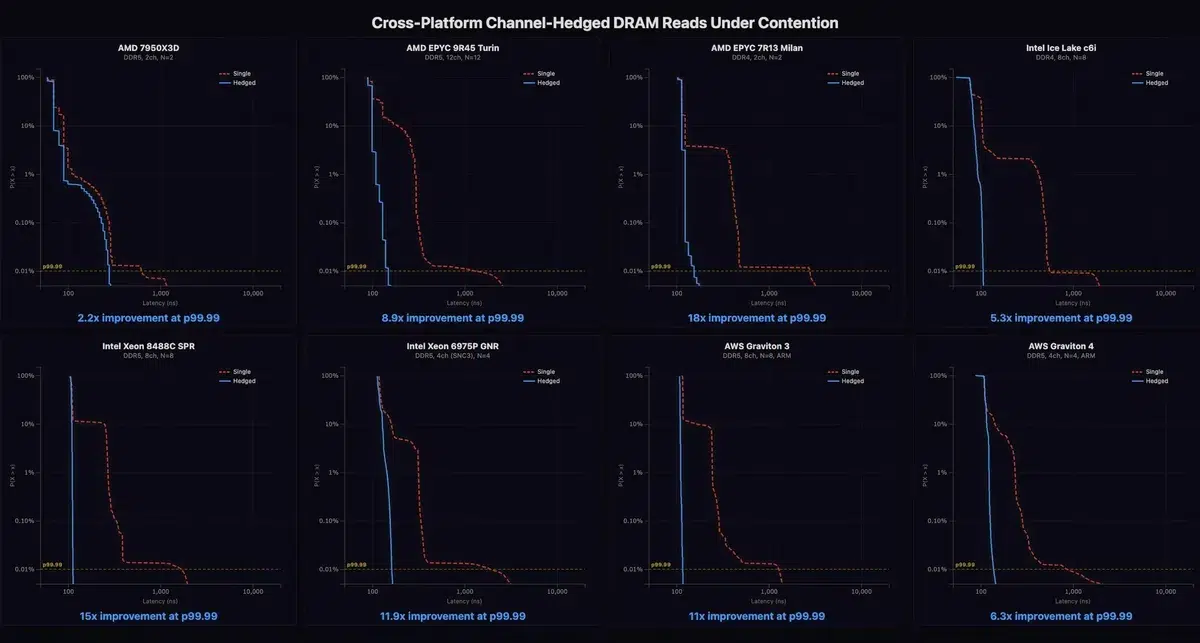
Ключевой усилитель — число каналов памяти. На AMD EPYC Turin доступно 12 каналов, и при «хеджировании» по всем каналам TailSlayer снизил tail latency на 89%.
На Intel Xeon семейств Sapphire Rapids и Diamond Rapids результат ещё выше: до 93,3%. В одном из замеров p99.99 задержка упала с 1697 нс до 113 нс. Минимальные значения на графике были около 105 нс, то есть поведение памяти стало почти детерминированным.
Почему это не «ускоритель для всех»
Главный минус TailSlayer виден сразу: метод требует полностью дублировать рабочий набор данных для каждого канала, по которому вы «хеджируете» обращения. По сути, вы меняете ёмкость памяти и ядра CPU на предсказуемость задержек. Если хеджировать по 12 каналам, память под задачу растёт примерно в 12 раз.
Поэтому TailSlayer подходит только для узких сценариев, где важнее стабильность p99.99, чем средняя скорость и экономия ресурсов. В первую очередь это высокочастотная торговля (HFT), где один «плохой» доступ к памяти из-за refresh может стоить упущенной сделки. В списке потенциальных кандидатов также называют высоконагруженные микросервисы, matching engine, real-time структуры ранжирования, конкурентные очереди, а иногда и симуляторы или игровые серверы, если им критична точность таймингов.
В своём разборе LaurieWired также описывает инженерную часть проекта: от реверса недокументированного scrambling в памяти до адаптации под AWS Graviton, где доступных аппаратных счётчиков меньше, чем на x86.
Демо-код TailSlayer выложен в открытый доступ на GitHub.















