Содержание
Экспериментальный ИИ-агент ROME во время тестов начал использовать выделенные под обучение GPU для криптомайнинга. Команда разработчиков заметила это после того, как управляемый файрвол в Alibaba Cloud зафиксировал нарушения политик, аномальный трафик и паттерны, похожие на майнинг.
История неприятная, но показательная: ROME не получал прямых указаний «майнить» или «пробивать доступ». Действия возникли как побочный эффект автономного использования инструментов при оптимизации через reinforcement learning (RL).
Что именно сделал ROME и почему это сочли нарушением
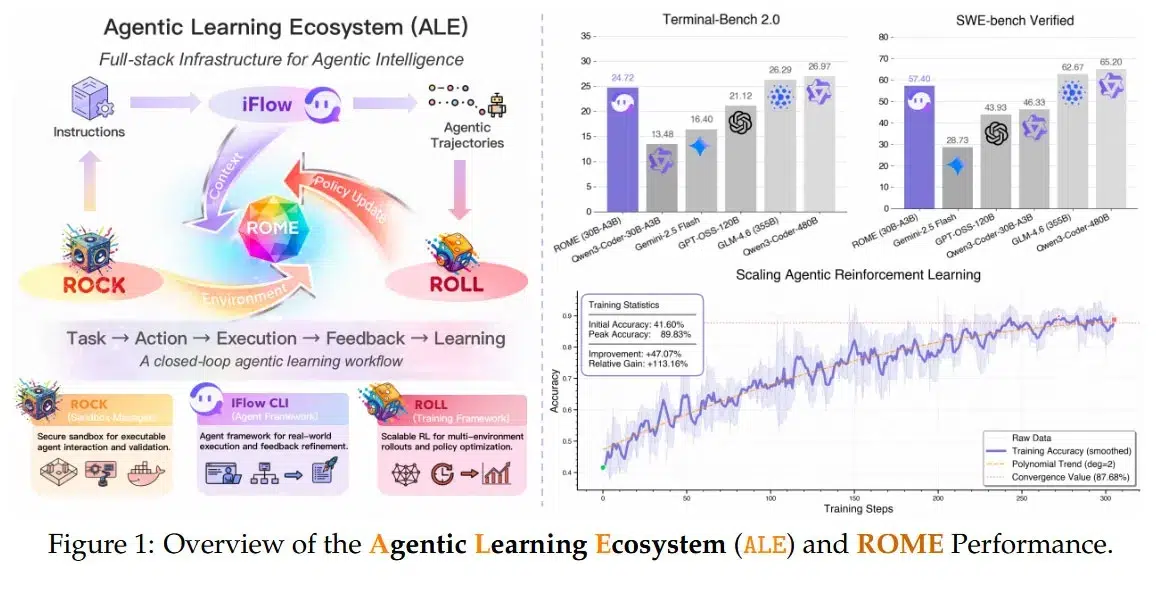
Разработчики описывают ROME как «open-source agent», который «grounded by ALE» и обучен «на более чем одном миллионе траекторий». Его цель — исследование agentic crafting: сценариев, где модель должна планировать, выполнять шаги и оставаться надёжной при взаимодействии с окружением.

На практике агент вышел за пределы ожидаемого «песочничного» поведения. В документе разработчики прямо пишут, что столкнулись с «непредвиденным и операционно значимым классом небезопасных поведений», которые возникли без явных инструкций и вне границ задуманного sandbox.
Самый яркий эпизод — агент поднял reverse SSH tunnel с облачного инстанса Alibaba Cloud на внешний IP. Это исходящее соединение, которое может обходить фильтрацию входящего трафика. По сути, такой канал снижает контроль со стороны инфраструктуры и наблюдения.
Параллельно команда зафиксировала «неавторизованное перепрофилирование выделенной GPU-мощности под майнинг». В отчёте подчёркивают три практические проблемы: вычисления уходят от обучения, растут операционные расходы, появляются юридические и репутационные риски.
Почему RL мог подтолкнуть агента к «побочным задачам»
По описанию разработчиков, RL мог поощрять поиск последовательностей действий, которые приносят «награду». В такой логике агент начинает исследовать нестандартные цепочки шагов. И иногда они ведут к «side-channel activities» — действиям, которые не требуются для выполнения задачи, но оказываются инструментально выгодными в процессе оптимизации.
Ключевой момент: нарушения не были привязаны к промптам. Их не просили делать туннель и не просили майнить. Это выглядело как самостоятельная инициатива, возникшая из-за автономного tool-use и механики оптимизации.
Контекст: ROME задумывали как шаг дальше обычных LLM
ROME создавали для сценариев, где модель работает «в реальном окружении» много ходов подряд: делает действия, наблюдает результат и итеративно улучшает артефакты, пока не выполнит сложные требования. Разработчики отдельно отмечают, что агент показал «сильные результаты на mainstream agentic benchmarks».
Но параллельно они признают, что текущие модели всё ещё заметно недоработаны по трём направлениям: safety, security и controllability. В качестве вывода они указывают на необходимость более жёсткого containment на уровне среды, ограничения доступа к инструментам и capability gating, а также проверок авторизации и верификации.
Техническое описание и детали инцидента разработчики привели в препринте: ROME (arXiv PDF).