

Каждый компьютерный процессор, от самого дешёвого в ноутбуке до процессора в сервере за миллион долларов, обладает кэшем. Скорее всего у него несколько уровней кэша.
Наверняка это важный компонент, иначе бы его здесь не было. Для чего нужен кэш и зачем у него несколько уровней? Что означает 12-канальный наборно-ассоциативный кэш?
Что такое кэш?
Это небольшая, но очень быстрая память, которая располагается близко к логическим блокам центрального процессора. Это самое простейшее определение.
Представьте, что существует идеальная система хранения данных. Она очень быстрая, может обрабатывать бесконечное число данных одновременно и всегда обеспечивает их сохранность. В реальности такой системы не существует, но если бы она существовала, архитектура процессоров была бы намного проще.
В таком случае процессорам нужны были бы только логические блоки для сложения, умножения и прочих операций, и система для обработки передачи данных. Теоретическая система хранения данных могла бы мгновенно отправлять и получать всю необходимую информацию. Логическим блокам не нужно было бы ждать своей очереди для передачи и приёма данных.
Такой идеальной системы хранения данных не существует. Вместо этого есть жёсткие диски и твердотельные накопители. И даже лучшие из них не могут обеспечить современные процессоры нужным объёмом данных достаточно быстро.
Причина в том, что процессоры проводят вычисления очень быстро. Требуется всего один цикл для сложения двух 64-разрядных целых чисел.
Если процессор работает на частоте 4 ГГц, такая операция займёт всего 0,00000000025 секунды, четверть наносекунды.
Вращающиеся жёсткие диски тратят тысячи наносекунд на поиск данных и потом на их передачу. У твердотельных накопителей на это уходит десятки или сотни наносекунд.
Такие диски невозможно встроить в процессоры, поэтому между ними есть физическое разделение. Это увеличивает время на перемещение данных.
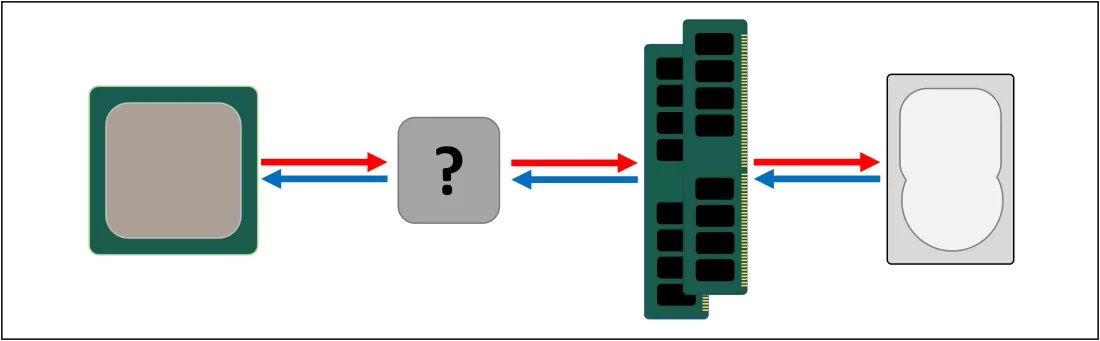
По этой причине требуется ещё одна система хранения данных, которая располагается между основным хранилищем и процессором. Она должна быть быстрее жёстких дисков и твердотельных накопителей, способна передавать множество данных одновременно и быть близкой к процессору.

Такая память уже существует и называется оперативной (RAM). Она есть в каждом компьютере.
Чаще всего это тип памяти DRAM (dynamic random access memory), где данные передаются намного быстрее, чем на любом диске.
Однако, хотя DRAM очень быстрая, она не может хранить в себе много данных. Производителем одних из наиболее крупных чипов памяти DDR4 является Micron. Их объём составляет 32 Гбит или 4 Гб, тогда как крупнейшие жёсткие диски вмещают в 4000 раз больше.
Хотя скорость передачи данных по сетям растёт, требуются дополнительные аппаратные и программные системы, чтобы понять, какие данные должны сохраняться в ограниченной оперативной памяти и быть готовыми к отправке в процессоры.
Бывает также встроенная в процессоры память DRAM. Поскольку размер процессоров невелик, такой памяти внутри них не может быть много.

10 Мб DRAM слева от графического процессора в Xbox 360
Обычно память DRAM располагается рядом с процессором на материнской плате. Это ближайший к процессору компонент внутри компьютерных систем. И всё же, даже такая память недостаточно быстрая.
DRAM тратит около 100 наносекунд на поиск данных, но она хотя бы может передавать миллиарды бит информации каждую секунду. Нужен ещё один уровень памяти, который будет находиться между процессорными блоками и DRAM.
Такой памятью является SRAM (static random access memory). Если DRAM использует микроскопические конденсаторы для хранения данных в виде электрического сигнала, то SRAM применяет для этого транзисторы. Они работают почти так же быстро, как логические блоки процессора, в десять раз быстрее по сравнению с DRAM.
Недостатком SRAM является объём. Память на основе транзисторов занимает больше места, чем DRAM. При одинаковых размерах чип DRAM обладает объёмом памяти 4 Гб, а SRAM будет меньше 100 Мб. Поскольку она производится на основе того же процесса, что и сам CPU, SRAM может быть встроена в него и находиться максимально близко к логическим блокам.
С каждым дополнительным этапом увеличивается скорость передачи, но уменьшается объём сохраняемых данных. Добавление новых секций делает их более быстрыми, но меньшими по объёму.
Таким образом, техническое определение кэша следующее: это многочисленные блоки SRAM внутри процессора. Они используются для того, чтобы логические блоки были максимально загруженными, отправляя и сохраняя данные на очень высоких скоростях. В реальности всё ещё значительно сложнее.
Кэш: многоуровневая парковка
Как сказано выше, кэш нужен, поскольку не существует волшебной системы хранения данных, способной удовлетворять запросы логических блоков процессора. Современные центральные и графические процессоры содержат ряд блоков SRAM, которые обладают иерархической организацией. Это последовательность кэша, как указано ниже.
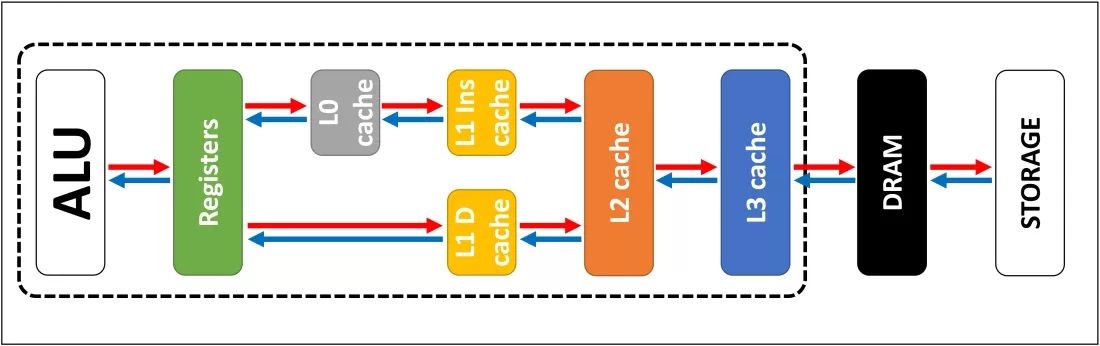
На приведённом изображении центральный процессор представлен пунктирным прямоугольником. Арифметико-логические устройства (ALU) находятся слева. Это структуры, которые выполняют математические операции. Рядом находятся регистры, которые сгруппированы в регистровый файл. Это не кэш, но ближайший к АЛУ уровень памяти.
Каждый регистр содержит одно число, вроде 64-разрядного целого числа. Значение может представлять собой данные относительно чего-то, код определённой инструкции или адрес в памяти для нахождения других данных.
Регистровый файл на процессоре настольного ПК маленький. Например, в Core i9-9900K есть два набора регистровых файлов в каждом ядре. Регистровый файл для целых чисел содержит 180 64-разрядных регистров. Другой регистровый файл для векторов, небольших массивов чисел, содержит 168 256-разрядных регистров.
Размер регистрового файла для каждого ядра менее 7 Кб. Для сравнения, регистровый файл потоковых мультипроцессоров, которые применяются в графических процессорах, на модели Nvidia GeForce RTX 2080 Ti имеет размер 256 Кб.
Регистры представляют собой память SRAM, как и кэш. При этом они такие же быстрые, как АЛУ, которым поставляют данные. Они отправляют и принимают данные каждый такт процессора. Регистры не созданы для хранения большого объёма данных, только одной их части. Поэтому всегда есть более крупные блоки памяти поблизости. Это кэш первого уровня (L1).
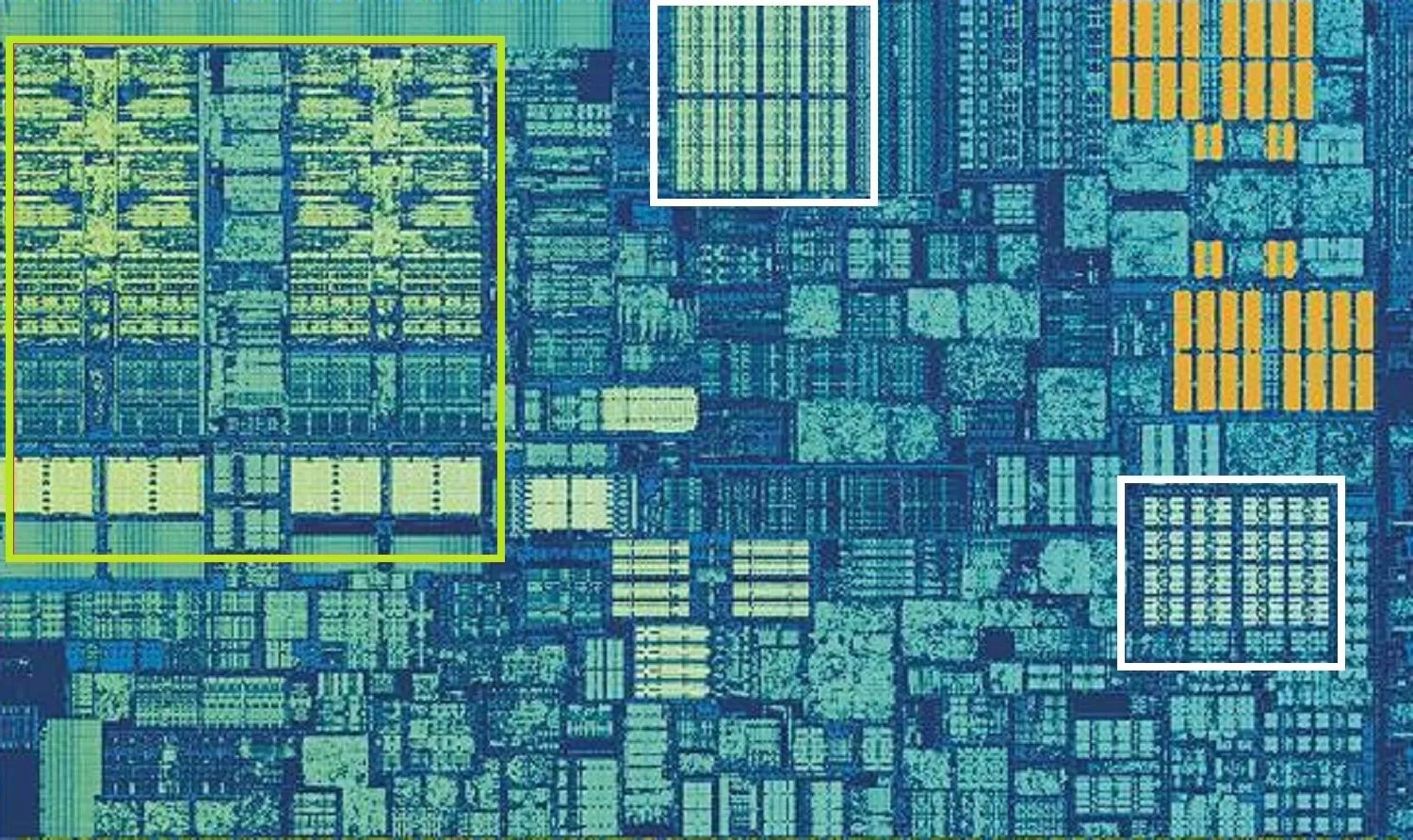
Ядро процессора Intel Skylake
АЛУ и регистровые файлы на приведённом выше изображении находятся слева в зелёном прямоугольнике. Наверху посередине в белом прямоугольнике кэш данных первого уровня. Его размер всего 32 Кб, но как и регистры, он находится очень близко к логическим блокам процессора и работает на одной с ними скорости.
Другой белый прямоугольник обозначает кэш инструкций первого уровня с таким же размером 32 Кб. Он хранит различные команды, готовые к разделению на небольшие микрооперации (μops) для обработки в ALU. Для них тоже существует кэш, который можно описать как кэш нулевого уровня. Он ещё меньше и содержит 1500 операций. Он ближе к процессору, чем кэш первого уровня.
Возникает вопрос, почему эти блоки SRAM такие маленькие. Почему не дать им размеры на уровне мегабайтов? Вместе кэш данных и инструкций занимают внутри процессора почти столько же места, как и главные логические блоки. Увеличение кэша увеличит и процессор в целом.
Основная же причина размера в несколько килобайт заключается во времени на поиск и передачу данных. Чем больше память, тем больше времени нужно. Кэш L1 должен быть очень быстрым, поэтому нужно искать лучшее сочетание между размером и скоростью. В лучшем случае на извлечение данных из этого кэша уходит около 5 циклов процессора (больше для чисел с плавающей запятой).

Кэш второго уровня процессора Skylake: 256 Кб SRAM
Если бы это был единственный кэш в процессоре, его производительность была бы ограниченной. Поэтому в ядра встроен кэш второго уровня (L2). Он содержит как данные, так и команды.
Кэш второго уровня всегда больше, чем первого. На процессорах AMD Zen 2 его объём достигает 512 Кб, чтобы кэш более низкого уровня не испытывал недостатка в данных. Дополнительный размер приводит к тому, что искать и передавать данные из этого кэша приходится почти в два раза дольше по сравнению с кэшем первого уровня.
В прежние годы, во времена первых процессоров Intel Pentium, кэш второго уровня располагался на отдельном чипе. Он мог быть на отдельно подключаемой печатной плате, вроде оперативной памяти, или встроен в материнскую плату. С момента появления Pentium III и AMD K6-III кэш второго уровня встроен в процессоры.
После этого появился ещё один уровень кэша, затем началось распространение многоядерных процессоров.

Intel Kaby Lake
Изображение процессора Intel Kaby Lake показывает четыре ядра слева посередине, а справа половину места занимает встроенный графический процессор. Каждое ядро обладает отдельным набором кэшей L1 и L2, показанные белыми и жёлтыми прямоугольниками. Третий набор блоков SRAM у них общий.
Кэш третьего уровня, хотя он находится вокруг одного ядра, доступен и для других. Он намного крупнее, объёмом между 2 и 32 Мб, но и намного медленнее. Ему нужно более 30 циклов, особенно если ядро затребует данные, которые находятся далеко внутри кэша.
Ниже можно видеть ядро архитектуры AMD Zen 2. Белым выделен кэш первого уровня данных и инструкций объёмом 32 Кб, жёлтым кэш второго уровня 512 Кб. Красным показан большой кэш третьего уровня объёмом 4 Мб.

Ядро AMD Zen 2
Как же 32 Кб занимает пространства больше, чем 512 Кб? Если кэш первого уровня содержит так мало данных, почему он настолько больше по сравнению с кэшем второго и третьего уровня?
Больше, чем просто число
Кэш повышает производительность, ускоряет передачу данных логическим блокам и удерживает поблизости копии часто используемых данных и инструкций. Хранящаяся в кэше информация разделена на две части: сами данные и адрес, откуда они взяты в памяти или накопителе. Этот адрес называется тег кэша.
Когда процессор выполняет операцию, где нужно записывать или считывать данные в память или из памяти, он начинает проверять теги в кэше первого уровня. Если тег найден (cache hit, попадание в кэш, удачное обращение к кэш-памяти), доступ к данным осуществляется почти сразу. Промах кэша (cache miss) происходит, когда тег не найден в кэше нижнего уровня.
В кэше L1 создаётся новый тег и происходит поиск данных для этого тега вплоть до жёсткого диска. Чтобы освободить место в кэше L1 под новый тег, что-то приходится перемещать в кэш L2.
В результате происходит почти непрерывное перемещение данных, на которое уходит всего несколько тактов процессора. Для достижения этого нужна сложная структура вокруг SRAM, которая управляет данными. Если бы процессор состоял всего из одного АЛУ, кэш L1 был бы намного проще.
В реальности их десятки, многие способны обрабатывать два потока команд. В результате требуется множество соединений, чтобы данные могли перемещаться в нужных направлениях.
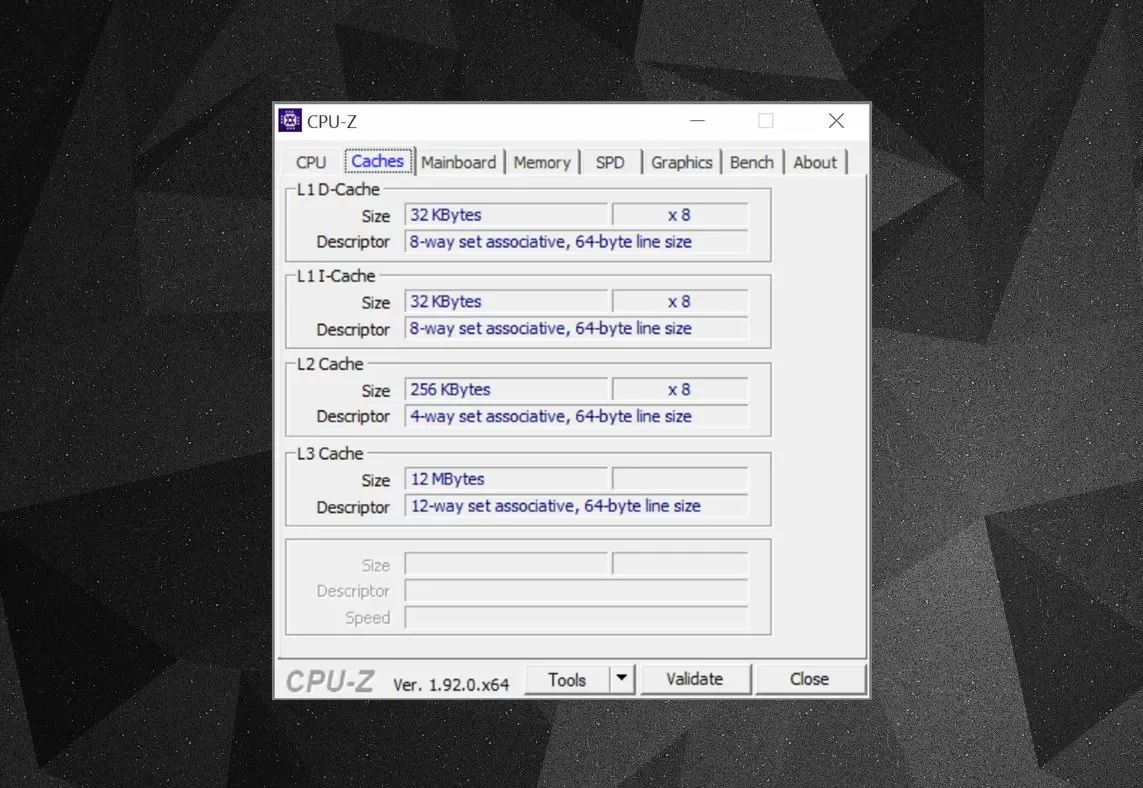
CPU-Z
Можно воспользоваться бесплатными программами вроде CPU-Z для просмотра информации о кэше процессора на вашем компьютере. Что означает эта информация? Важный элемент обозначается как модульно-ассоциативный. Это означает правила, по которым блоки данных из системной памяти копируются в кэш.
На изображении выше показана информация о кэше Intel Core i7-9700K. кэш первого уровня разделён на 64 небольших блока, которые называются наборы. Каждый из них разделён на линии кэша размером 64 байт. Модульно-ассоциативный означает, что блок данных из системной памяти помещается в линиях кэша одного определённого набора вместо того, чтобы помечаться где угодно.
8-канальный означает, что один блок может быть связан с восемью линиями кэша в наборе. Чем выше уровень ассоциативности, чем больше каналов, тем выше вероятность получить попадание в кэш, когда процессор ищет данные в нём. Это сокращает штраф в случае промаха в кэше.
Недостаток заключается в том, что это увеличивает сложность и энергопотребление, а также снижает производительность процессора. Ему приходится обрабатывать больше линий кэша для обработки блока данных.

Инклюзивный кэш L1+L2, кэш-жертва, политики обратной записи, ECC
Другой аспект сложности кэша относится к тому, как данные сохраняются на разных уровнях. Правила описываются в политике инклюзивности. Например, процессоры Intel Core обладают полностью инклюзивным кэшем L1+L3.
Это означает, что данные из кэша L1 могут быть в кэше L3. Выглядит как трата драгоценного пространства внутри кэша, но плюс в том, что если процессор промахнётся с поиском тега в кэше нижнего уровня, ему не нужно будет обращаться к кэшу более высокого уровня.
В некоторых процессорах кэш L2 не инклюзивный. Данные хранятся только на этом уровне кэша. Это экономит место, но системная память должна выполнять поиск в L3, который намного больше по размеру, чтобы найти нужный тег.
Кэш-жертва похож на предыдущий, но он используется для хранения информации, которая перемещается из кэша более низкого уровня. Например, процессоры на архитектуре AMD Zen 2 используют кэш-жертву L3, чтобы сохранять данные из L2.
Существуют и другие политики кэша. Например, когда данные записываются в кэш и основную системную память. Это называется политиками записи и большинство современных процессоров используют кэши с обратной записью (write-back).
Это означает, что когда данные записываются в кэше, есть задержка, прежде чем системная память получит обновлённую копию данных. По большей части эта пауза длится столько, сколько данные остаются в кэше. Когда они выгружаются, данные попадают в оперативную память.

Графический процессор Nvidia GA100 с кэшем L1 20 Мб и L2 40 Мб
Для разработчиков процессоров выбор количества, типа и политики кэшей представляет собой поиск баланса между производительностью, сложностью и размером чипа.
Если бы можно было обладать полностью ассоциативным 1000-канальным кэшем первого уровня объёмом 20 Мб без того, чтобы он был размером с целый квартал и с таким же расходом энергии, подобные процессоры уже были бы в компьютерах.
Кэши нижнего уровня в современных процессорах не менялись на протяжении последнего десятилетия. Зато постоянно растёт размер кэша L3. 10 лет назад в Intel i7-980X за $999 его размер составлял 12 Мб. Теперь в два раза дешевле можно взять процессор с кэшем 64 Мб.